Running H2O on Hadoop¶
The following tutorial will walk the user through the download or build of H2O and the parameters involved in launching H2O from the command line.
- Download the latest H2O release:
$ wget http://h2o-release.s3.amazonaws.com/h2o/master/1/h2o-2.8.4.1.zip
- Prepare the job input on the Hadoop Node by unzipping the build file and changing to the directory with the Hadoop and H2O’s driver jar files.
$ unzip h2o-2.8.4.1.zip
$ cd h2o-2.8.4.1/hadoop
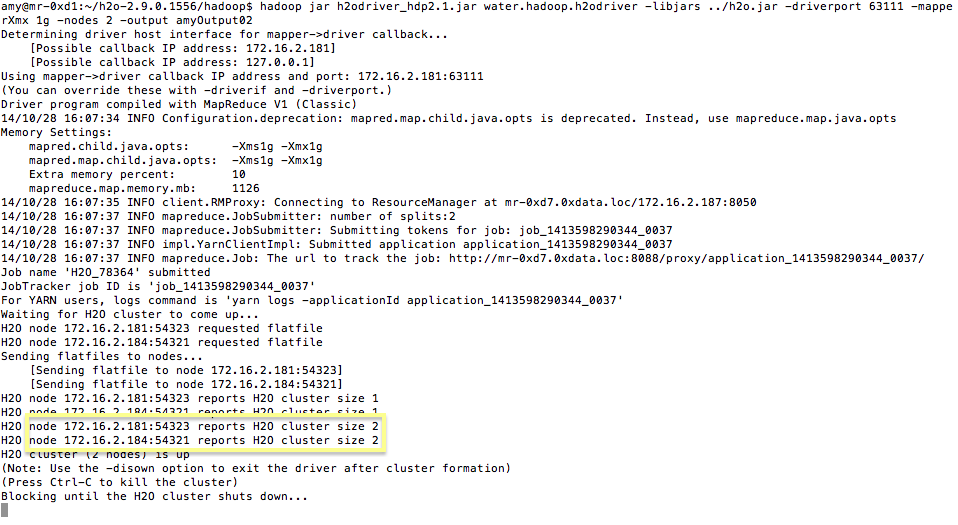
- To launch H2O nodes and form a cluster on the Hadoop cluster, run:
$ hadoop jar h2odriver_hdp2.1.jar water.hadoop.h2odriver -libjars ../h2o.jar -mapperXmx 1g -nodes 1 -output hdfsOutputDirName
- For each major release of each distribution of Hadoop, there is a driver jar file that is required to launch H2O. Currently available driver jar files in each build of H2O include h2odriver_cdh5.jar, h2odriver_hdp2.1.jar, and mapr2.1.3.jar.
- The above command launches a 1g node of H2O. We recommend you launch the cluster with four times the memory of your data file.
- mapperXmx is the mapper size or the amount of memory allocated to each node.
- nodes is the number of nodes requested to form the cluster.
- output is the name of the directory created each time a H2O cloud is created so it is necessary for the name to be unique each time it is launched.
4. To monitor your job, direct your web browser to your standard job tracker Web UI. To access H2O’s Web UI, direct your web browser to one of the launched instances. If you are unsure where your JVM is launched, review the output from your command after the nodes has clouded up and formed a cluster. Any of the nodes’ IP addresses will work as there is no master node.