Using H2O Sparkling Water with Databricks¶
Databricks provides a cloud-based, integrated workspace on top of Apache Spark for developers and data scientists. This section shows how to use Sparking Water with Databricks.
Requirements¶
- Databricks account
- AWS account
- Sparkling Water jar
- Login to your Databricks account and create a new library containing Sparkling Water. Note that you can use the Maven coordinates of the Sparkling Water package, for example:
h2o:sparkling-water-examples_2.10:1.5.6. (This version works with Spark 1.5.)
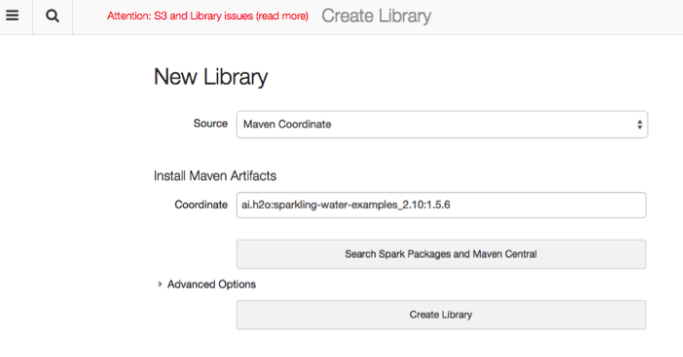
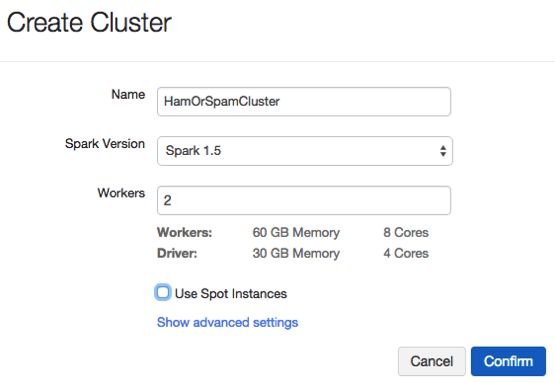
- Create a new cluster. Note that in this example, we are using Spark 1.5, and the name of the cluster is “HamOrSpamCluster”.
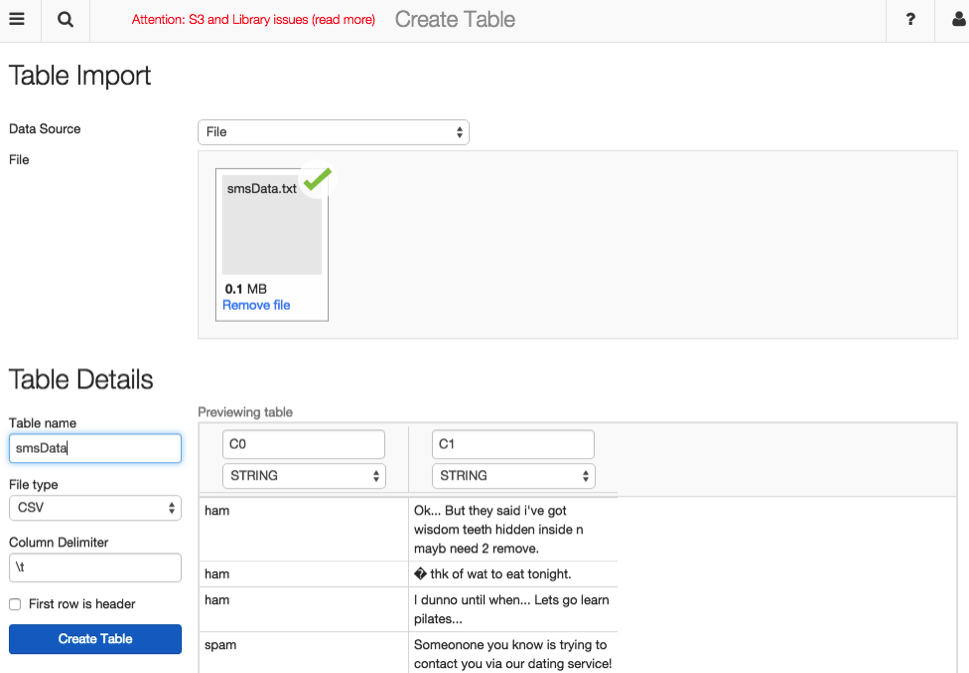
- Upload data. In this example, we are using Table Import and uploading the smsData.txt file.
Your environment is ready after the data is uploaded. At this point, you can create a Databricks notebook, connect it to “HamOrSpamCluster”, and start building a predictive model. A demo of this can be found in the Databricks and H2O Make it Rain with Sparkling Water blog post.
Using PySparkling with Databricks¶
In order to use PySparkling with Databricks, the PySparkling module has to be added as a library to the current cluster. PySparkling can be added as library in two ways: you can either upload the PySparkling source zip file or add the PySparkling module from PyPI. If you choose to upload PySparkling zip file, don’t forget to add libraries for following python modules: request, tabulate and future. The PySparkling zip file is available in the py/dist directory in both the built Sparkling Water project and the downloaded Sparkling Water release.