Running PySparkling on Databricks Azure Cluster¶
Sparkling Water, PySparkling and RSparkling can be used on top of Databricks Azure Cluster. This tutorial is the PySparkling.
For Scala Sparkling Water, please visit Running Sparkling Water on Databricks Azure Cluster and for RSparkling, please visit Running RSparkling on Databricks Azure Cluster.
To start Sparkling Water H2OContext on Databricks Azure, the steps are:
Login into Microsoft Azure Portal
Create Databricks Azure Environment
In order to connect to Databricks from Azure, please make sure you have created user inside Azure Active Directory and using that user for the Databricks Login.
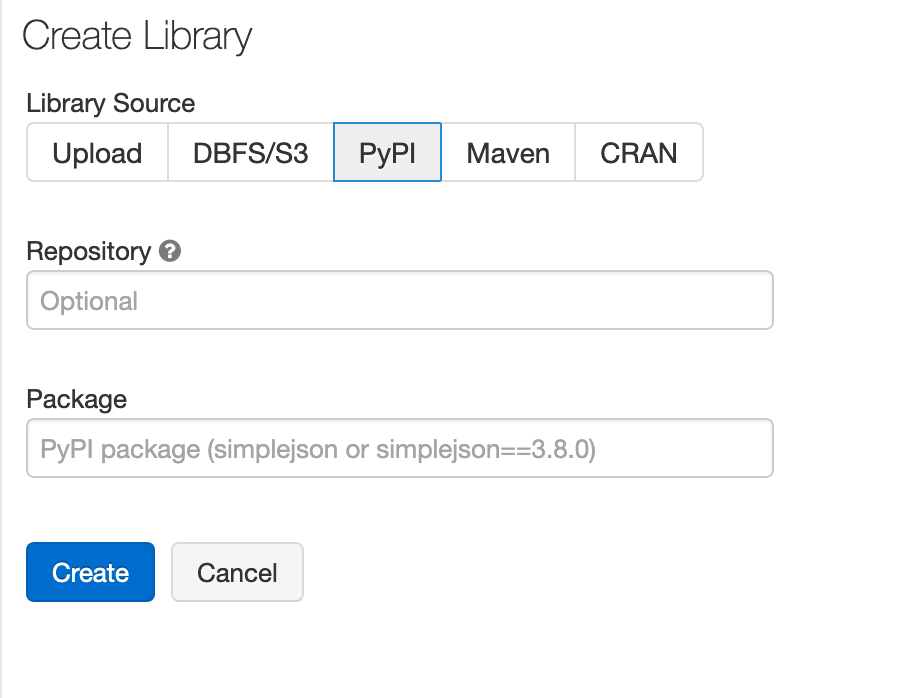
Add PySparkling dependency
In order to create the Python library in Databricks, go to Libraries, select PiPy as the library source and type in:
h2o_pysparkling_2.3for the latest PySparkling for Spark 2.3.The advantage of adding the library from PiPy, instead of uploading manually, is that the latest version is always selected and also, the dependencies are automatically resolved.
You can configure each cluster manually and select which libraries should be attached or you can configure the library to be attached to all future clusters. It is advised to restart the cluster in case you attached the library to already running cluster to ensure the clean environment.
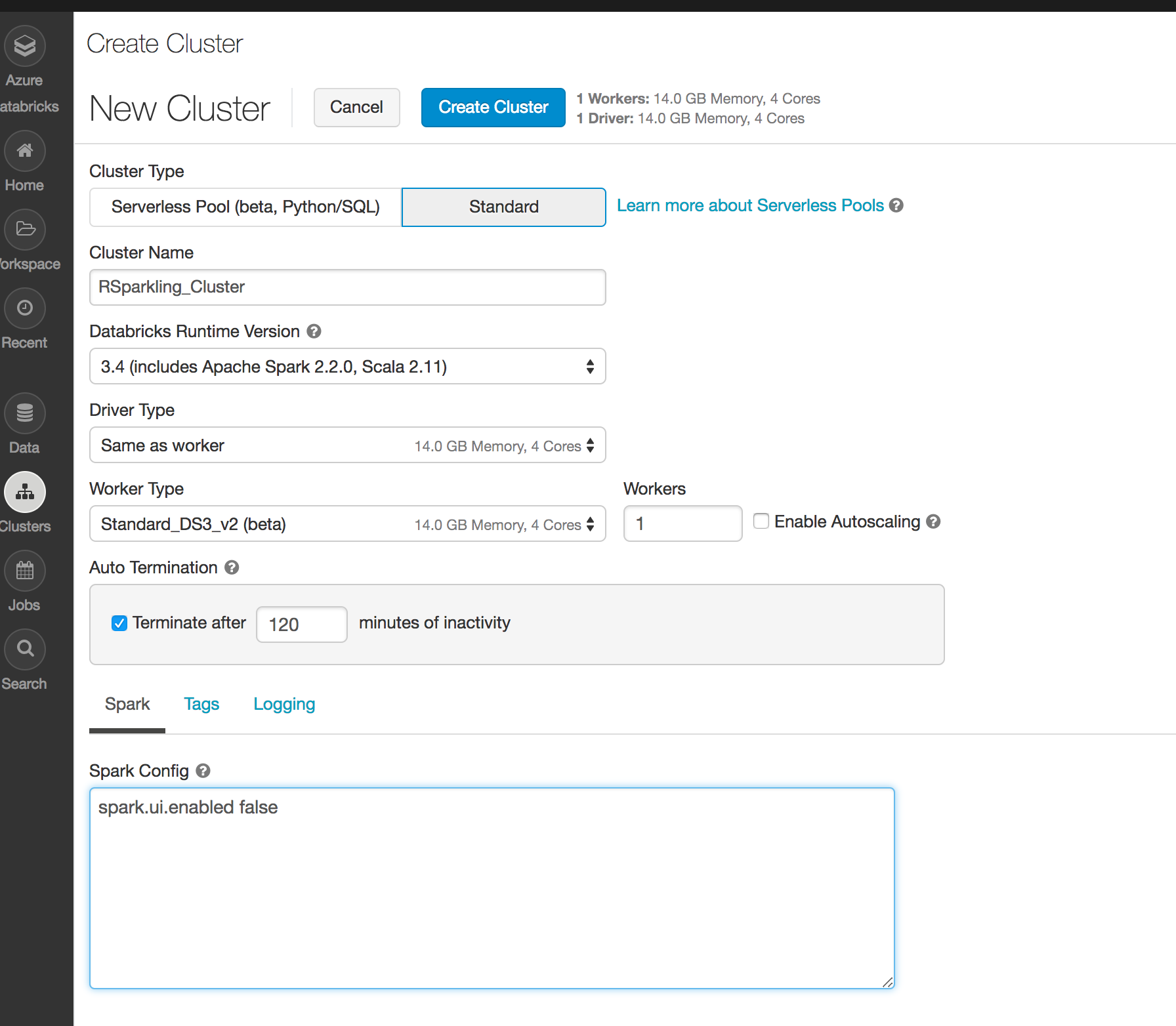
Create the cluster
Make sure the library is attached to the cluster
Select Spark 2.3.4
Create Python notebook and attach it to the created cluster. To start
H2OContext, the init part of the notebook should be:from pysparkling import * hc = H2OContext.getOrCreate()
And voila, we should have
H2OContextrunning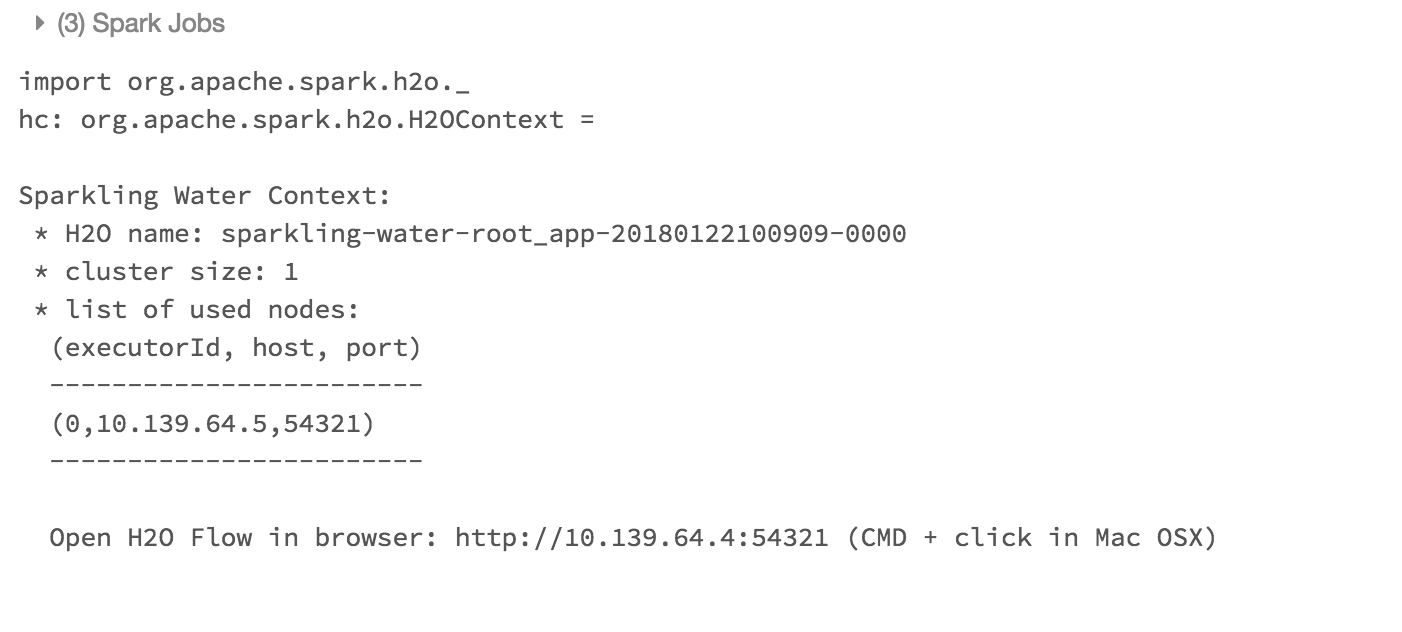
Flow is accessible via the URL printed out after H2OContext is started. Internally we use open port 9009. If you have environment where different port is open on your Azure Databricks cluster, you can configure it via
spark.ext.h2o.client.web.portor corresponding setter onH2OConf.