Starting H2O¶
There are a variety of ways to start H2O, depending on which client you would like to use.
From R¶
To use H2O in R, follow the instructions on the R download page.
From Python¶
To use H2O in Python, follow the instructions on the Python download page.
On Spark¶
To use H2O on Spark, follow the instructions on the Sparkling Water download page.
From the Command Line¶
You can use Terminal (OS X) or the Command Prompt (Windows) to launch H2O 3.0. When you launch from the command line, you can include additional instructions to H2O 3.0, such as how many nodes to launch, how much memory to allocate for each node, assign names to the nodes in the cloud, and more.
Note: H2O requires some space in the/tmpdirectory to launch. If you cannot launch H2O, try freeing up some space in the/tmpdirectory, then try launching H2O again.
For more detailed instructions on how to build and launch H2O, including how to clone the repository, how to pull from the repository, and how to install required dependencies, refer to the developer documentation.
There are two different argument types:
- JVM arguments
- H2O arguments
The arguments use the following format: java <JVM Options> -jar
h2o.jar <H2O Options>.
JVM Options¶
-version: Display Java version info.-Xmx<Heap Size>: To set the total heap size for an H2O node, configure the memory allocation option-Xmx. By default, this option is set to 1 Gb (-Xmx1g). When launching nodes, we recommend allocating a total of four times the memory of your data.Note: Do not try to launch H2O with more memory than you have available.
H2O Options¶
-hor-help: Display this information in the command line output.-name <H2OCloudName>: Assign a name to the H2O instance in the cloud (where<H2OCloudName>is the name of the cloud). Nodes with the same cloud name will form an H2O cloud (also known as an H2O cluster).-flatfile <FileName>: Specify a flatfile of IP address for faster cloud formation (where<FileName>is the name of the flatfile).-ip <IPnodeAddress>: specifies IP for the machine other than the defaultlocalhost, for example:
- IPv4:
-ip 178.16.2.223- IPv6:
-ip 2001:db8:1234:0:0:0:0:1(Short version of IPv6 with::is not supported.) Note: If you are selecting a link-local addressfe80::/96, it is necessary to specify the zone index (e.g.,%en0forfe80::2acf:e9ff:fe15:e0f3%en0) in order to select the right interface.
-port <#>: Specify a PORT used for REST API. The communication port will be the port with value +1 higher.-baseportspecifies starting port to find a free port for REST API, the internal communication port will be port with value +1 higher.-network <ip_address/subnet_mask>: Specify an IP addresses with a subnet mask. The IP address discovery code binds to the first interface that matches one of the networks in the comma-separated list; to specify an IP address, use-network. To specify a range, use a comma to separate the IP addresses:-network 123.45.67.0/22,123.45.68.0/24. For example,10.1.2.0/24supports 256 possibilities. IPv4 and IPv6 addresses are supported.
- IPv4:
-network 178.0.0.0/8- IPv6:
-network 2001:db8:1234:0:0:0:0:0/48(short version of IPv6 with::is not supported.)
-ice_root <fileSystemPath>: Specify a directory for H2O to spill temporary data to disk (where<fileSystemPath>is the file path).-flow_dir <server-side or HDFS directory>: Specify a directory for saved flows. The default is/Users/h2o-<H2OUserName>/h2oflows``(where ``<H2OUserName>is your user name).-nthreads <#ofThreads>: Specify the maximum number of threads in the low-priority batch work queue (where<#ofThreads>is the number of threads). The default is 99.-client: Launch H2O node in client mode. This is used mostly for running Sparkling Water.
H2O Internal Communication¶
By default, H2O selects the IP and PORT for internal communication automatically using the following this process (if not specified):
- Retrieve a list of available interfaces (which are up).
- Sort them with “bond” interfaces put on the top.
- For each interface, extract associated IPs.
- Pick only reachable IPs (that filter IPs provided by interfaces, such as awdl):
- If there is a site IP, use it.
- Otherwise, if there is a link local IP, use it. (For IPv6, the link IP 0xfe80/96 is associated with each interface.)
- Or finally, try to find a local IP. (Use loopback or try to use Google DNS to find IP for this machine.)
Notes: The port is selected by looking for a free port starting with port 54322. The IP, PORT and network selection can be changed by the following options:
-ipnetwork-port-baseport
Cloud Formation Behavior¶
New H2O nodes join to form a cloud during launch. After a job has started on the cloud, it prevents new members from joining.
- To start an H2O node with 4GB of memory and a default cloud name:
java -Xmx4g -jar h2o.jar - To start an H2O node with 6GB of memory and a specific cloud name:
java -Xmx6g -jar h2o.jar -name MyCloud - To start an H2O cloud with three 2GB nodes using the default cloud
names:
java -Xmx2g -jar h2o.jar & java -Xmx2g -jar h2o.jar & java -Xmx2g -jar h2o.jar &
Wait for the INFO: Registered: # schemas in: #mS output before
entering the above command again to add another node (the number for #
will vary).
Clouding Up: Cluster Creation¶
H2O provides two modes for cluster creation:
- Multicast based
- Flatfile based
Multicast¶
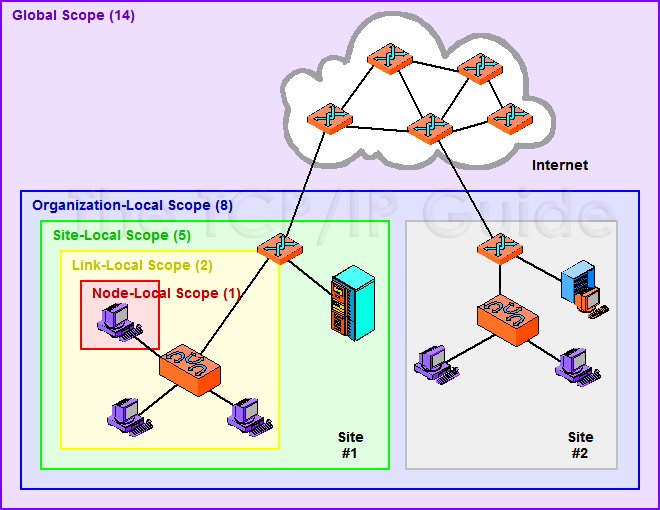
In this mode, H2O is using IP multicast to announce existence of H2O nodes. Each node selects the same multicast group and port based on specified shared cloud name (see -name option). For example, for IPv4/PORT a generated multicast group is 228.246.114.236:58614 (for cloud name michal),
for IPv6/PORT a generated multicast group is ff05:0:3ff6:72ec:0:0:3ff6:72ec:58614 (for cloud name michal and link-local address which enforce link-local scope).
For IPv6 the scope of multicast address is enforced by a selected node IP. For example, if IP the selection process selects link-local address, then the scope of multicast will be link-local. This can be modified by specifying JVM variable sys.ai.h2o.network.ipv6.scope which enforces addressing scope use in multicast group address (for example, -Dsys.ai.h2o.network.ipv6.scope=0x0005000000000000 enforces the site local scope. For more details please consult the
class water.util.NetworkUtils).
For more information about scopes, see the following image.
{kind=link}
Flatfile¶
he flatfile describes a topology of a H2O cluster. The flatfile definition is passed via the -flatfile option. It needs to be passed at each node in the cluster, but definition does not be the same at each node. However, transitive closure of all definitions should contains all nodes. For example, for the following definition
| Nodes | nodeA | nodeB | nodeC |
| Flatfile | A,B | A, B | B, C |
The resulting cluster will be formed by nodes A, B, C. The node A transitively sees node C via node B flatfile definition, and vice versa.
The flatfile contains a list of nodes in the form IP:PORT (each node on separated line, everything prefixed by # is ignored) which are going to compose a resulting cluster. For example, running H2O on a multi-node cluster allows you to use more memory for large-scale tasks (for example, creating models from huge datasets) than would be possible on a single node.
IPv4:
# run two nodes on 108
10.10.65.108:54322
10.10.65.108:54325
IPv6:
0:0:0:0:0:0:0:1:54321
0:0:0:0:0:0:0:1:54323
Web Server¶
The web server IP is auto-configured in the same way as internal communication IP, nevertheless the created socket listens on all available interfaces. A specific API can be specified with the -web_ip option.
Options¶
-web_ip: specifies IP for web server to expose REST API
Dual Stacks¶
Dual stack machines support IPv4 and IPv6 network stacks.
Right now, H2O always prefer IPV4, however the preference can be changed via JVM system options java.net.preferIPv4Addresses and java.net.preferIPv6Addresses.
For example:
-Djava.net.preferIPv6Addresses=true -Djava.net.preferIPv4Addresses=true- H2O will try to select IPv4-Djava.net.preferIPv6Addresses=true -Djava.net.preferIPv4Addresses=false- H2O will try to select IPv6