Data Sharing¶
Sparkling Water enables transformation between different types of Spark’s RDD and H2O’s H2OFrame, and vice versa.
Conversion Design¶
When converting from H2OFrame to RDD, a wrapper is created around the H2OFrame to provide an RDD-like API. In this case, no data is duplicated; instead, the data is served directly from the underlying H2OFrame.
Conversion in the opposite direction (i.e, from Spark RDD/DataFrame to H2OFrame) requires evaluation of the data stored in the Spark RDD and then transferring that from RDD storage into H2OFrame. However, data stored in H2OFrame is heavily compressed.
Exchanging the Data¶
The way that data is transferred between Spark and H2O differs based on the used Sparkling Water backend. (Refer to Sparkling Water Backends for more information about the Internal and External backends.)
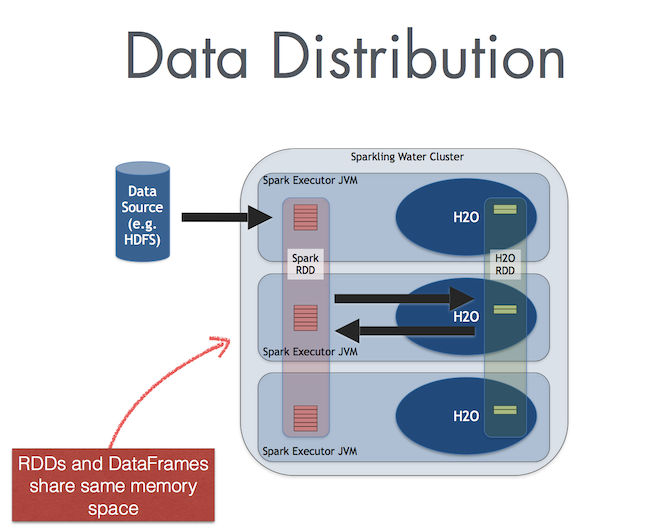
In the Internal Sparkling Water Backend, Spark and H2O share the same JVM, as is depicted on the following figure.
In the External Sparkling Water Backend, Spark and H2O are separated clusters, and data has to be sent between those clusters over the network.