Running Sparkling Water on Databricks Azure Cluster¶
Sparkling Water, PySparkling and RSparkling can be used on top of Databricks Azure Cluster. This tutorial is the Scala Sparkling Water.
For Pysparkling, please visit PySparkling on Databricks Azure Cluster and for RSparkling, please visit RSparkling on Databricks Azure Cluster.
To start Sparkling Water H2OContext on Databricks Azure, the steps are:
Login into Microsoft Azure Portal
Create Databricks Azure Environment
In order to connect to Databricks from Azure, please make sure you have created user inside Azure Active Directory and using that user for the Databricks Login.
Upload Sparkling Water assembly JAR as a library
In order to create the library in Databricks, go to Libraries, select Upload Java/Scala JAR and upload the downloaded assembly jar. If you download the official distribution, the assembly jar is located in
assembly/build/libsdirectory. The assembly Jar can be downloaded from our official download page.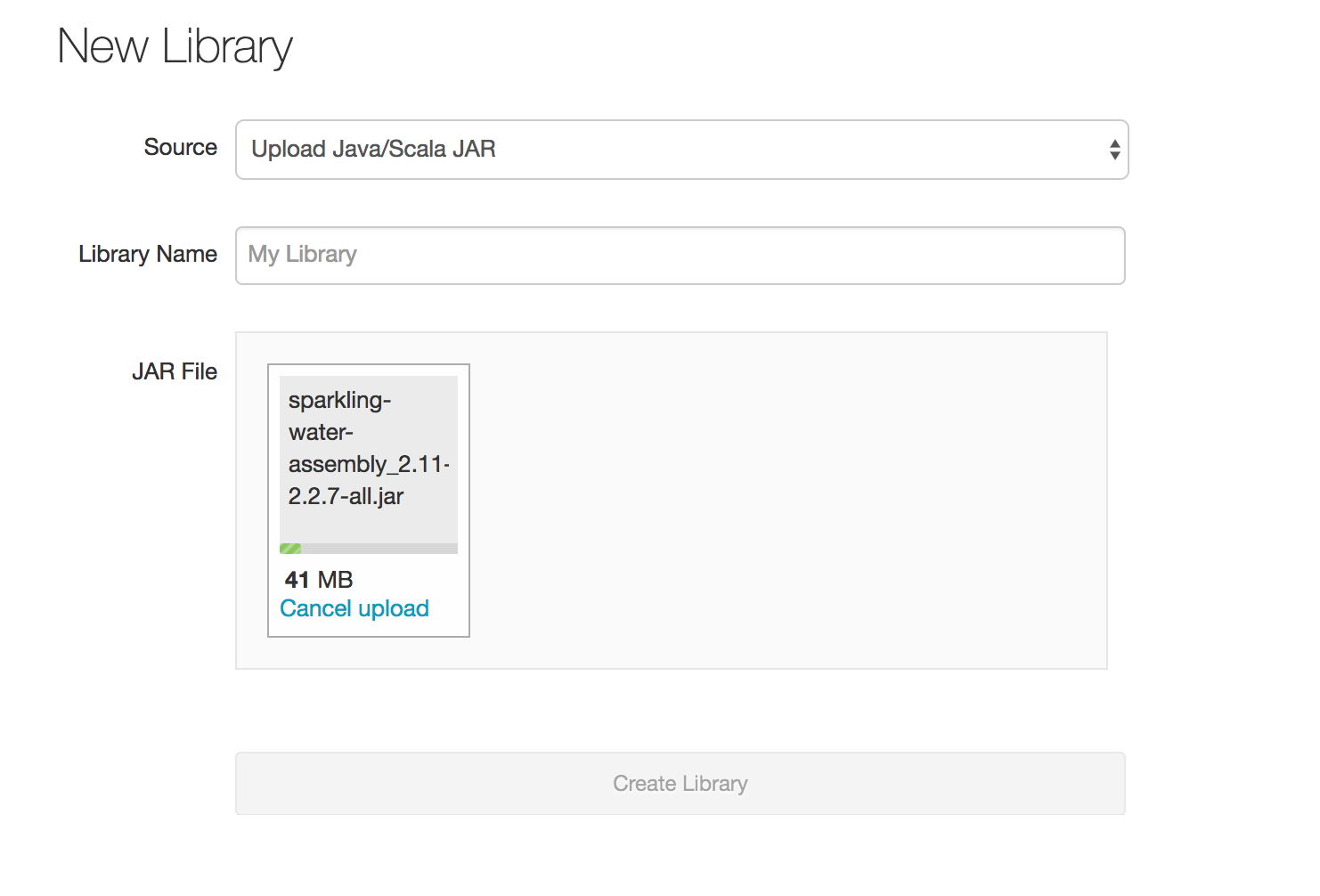
You can configure each cluster manually and select which libraries should be attached or you can configure the library to be attached to all future clusters. It is advised to restart the cluster in case you attached the library to already running cluster to ensure the clean environment.
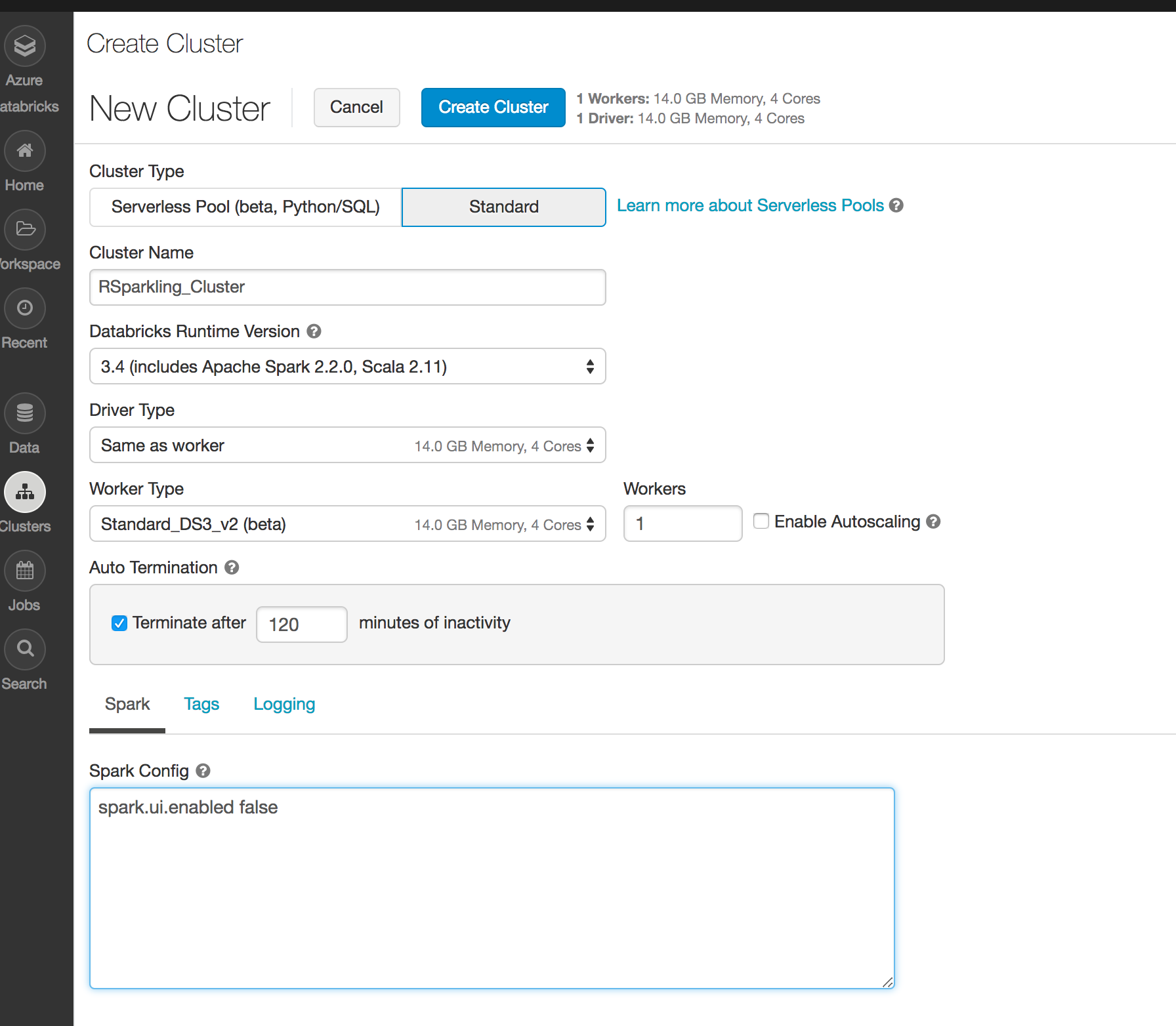
Create the cluster
- Make sure the assembly JAR is attached to the cluster
- For Sparkling Water 2.3.30 select Spark 2.3.3
It is advised to always use the latest Sparkling Water and Spark version for the given Spark major version.
Create Scala notebook and attach it to the created cluster. To start
H2OContext, the init part of the notebook should be:import org.apache.spark.h2o._ val hc = H2OContext.getOrCreate(spark)
And voila, we should have
H2OContextrunning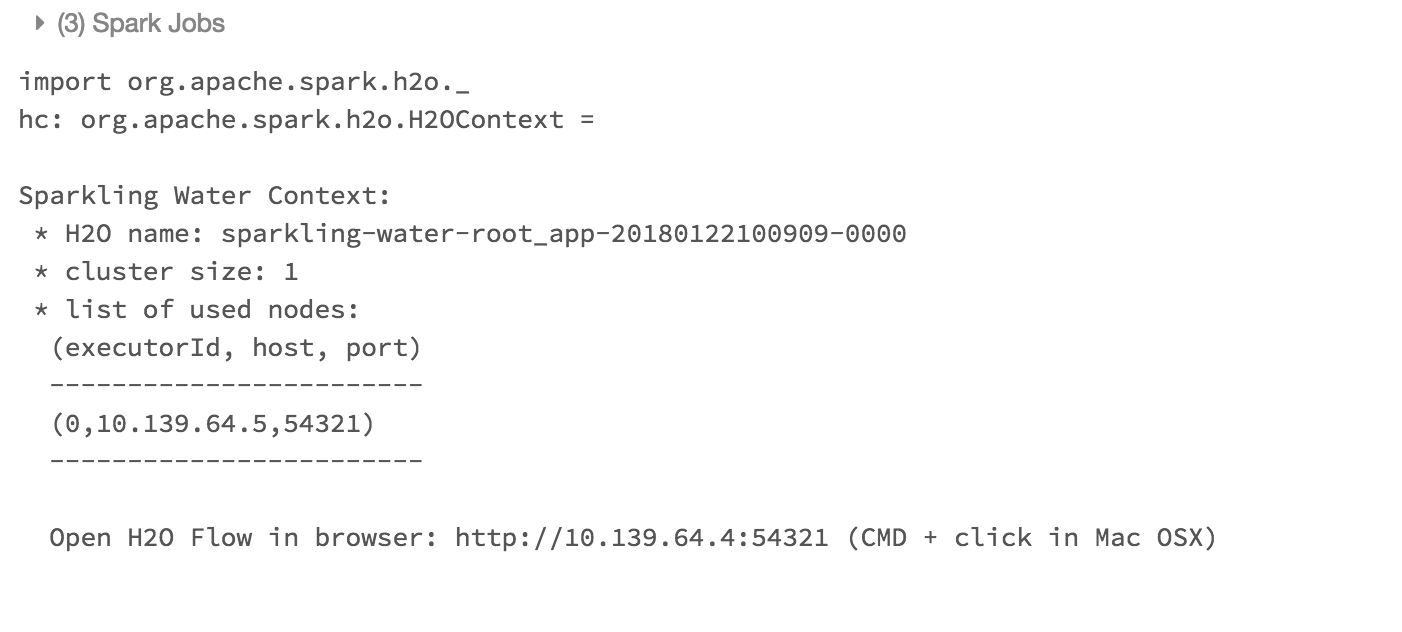
Please note that accessing H2O Flow is not currently supported on Azure Databricks.