Hadoop FAQ¶
Accessing Logs¶
Depending on whether you are using Hadoop with H2O and whether the job is currently running, there are different ways of obtaining the logs for H2O.
Note: Unless otherwise specified, the following methods work the same for the first version of H2O (H2O1) and H2O-dev (which uses a UI known as H2O-Flow).
Copy and email the logs to support@h2o.ai or submit them to h2ostream@googlegroups.com with a brief description of your Hadoop environment, including the Hadoop distribution and version.
Without Running Jobs¶
- If you are using Hadoop and the job is not running, view the logs by using the yarn logs -applicationId command. When you start an H2O instance, the complete command displays in the output:
amy@mr-0xb1:~/h2o-2.5.0.99999/hadoop$ hadoop jar h2odriver_hdp1.3.2.jar water.hadoop.h2odriver
-libjars ../h2o.jar -mapperXmx 10g -nodes 4 -output output903 -verbose:class
Determining driver host interface for mapper->driver callback...
[Possible callback IP address: 192.168.1.161]
[Possible callback IP address: 127.0.0.1]
Using mapper->driver callback IP address and port: 192.168.1.161:37244
(You can override these with -driverif and -driverport.)
Driver program compiled with MapReduce V1 (Classic)
Memory Settings:
mapred.child.java.opts: -Xms10g -Xmx10g -verbose:class
mapred.map.child.java.opts: -Xms10g -Xmx10g -verbose:class
Extra memory percent: 10
mapreduce.map.memory.mb: 11264
Job name 'H2O_74206' submitted
JobTracker job ID is 'job_201407040936_0030'
For YARN users, logs command is 'yarn logs -applicationId application_201407040936_0030'
Waiting for H2O cluster to come up...
In the above example, the command is specified in the next to last line (For YARN users, logs command is...). The command is unique for each instance. In Terminal, enter yarn logs -applicationId application_<UniqueID> to view the logs (where <UniqueID> is the number specified in the next to last line of the output that displayed when you created the cluster).
- Use YARN to obtain the stdout and stderr logs that are used for troubleshooting. To learn how to access YARN based on management software, version, and job status, see “Accessing YARN”.
Click the Applications link to view all jobs, then click the History link for the job.
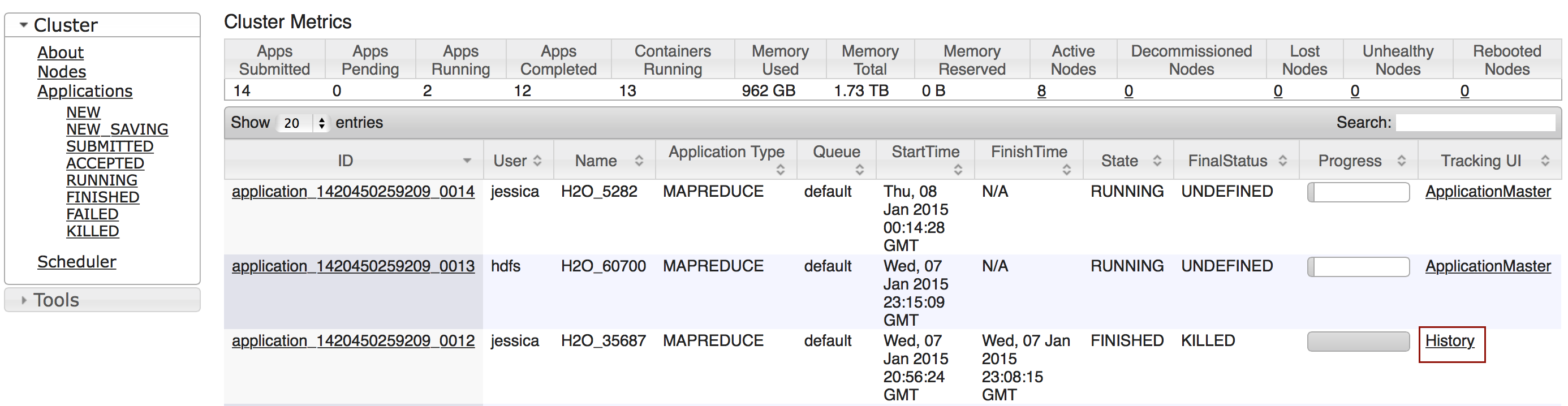
Click the logs link.
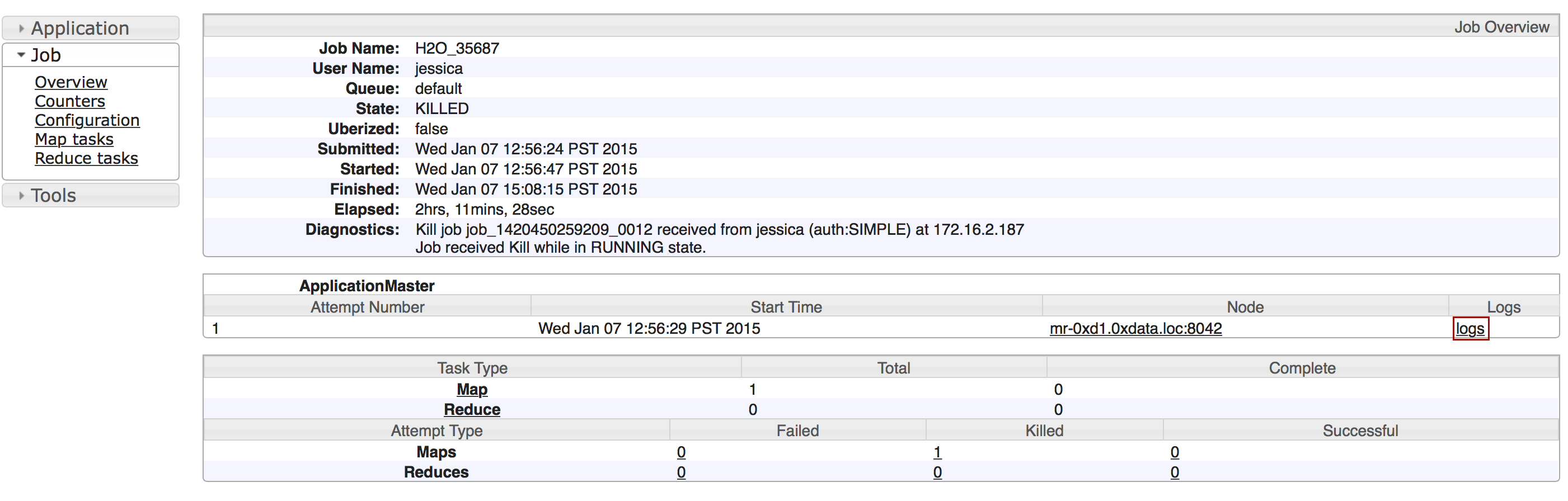
Copy the information that displays and send it in an email to support@h2o.ai.
With Running Jobs¶
If you are using Hadoop and the job is still running:
- Use YARN to obtain the stdout and stderr logs that are used for troubleshooting. To learn how to access YARN based on management software, version, and job status, see “Accessing YARN”.
Click the Applications link to view all jobs, then click the ApplicationMaster link for the job.
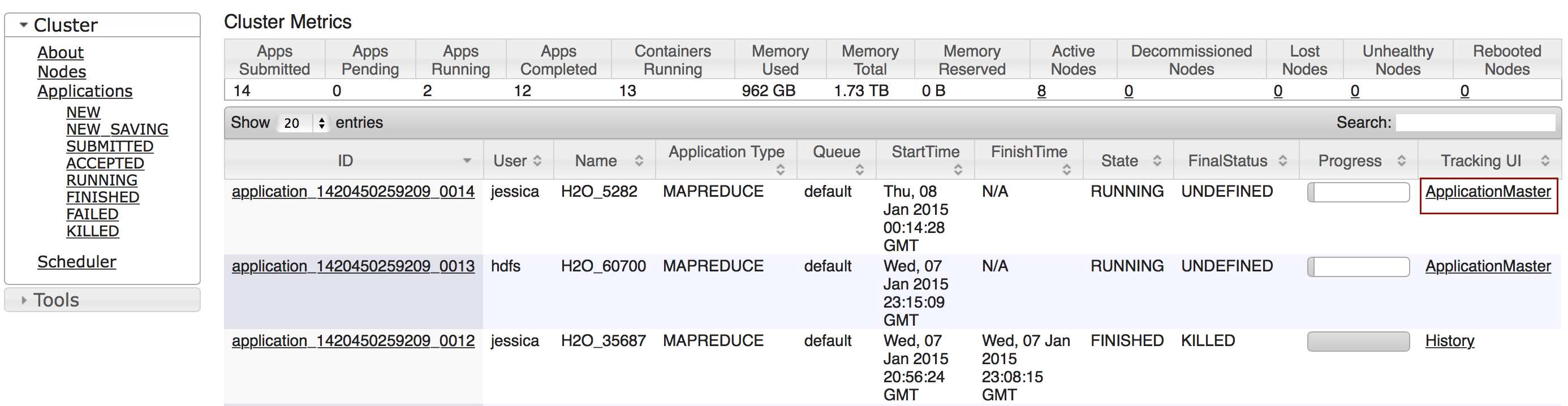
Select the job from the list of active jobs.

Click the logs link.
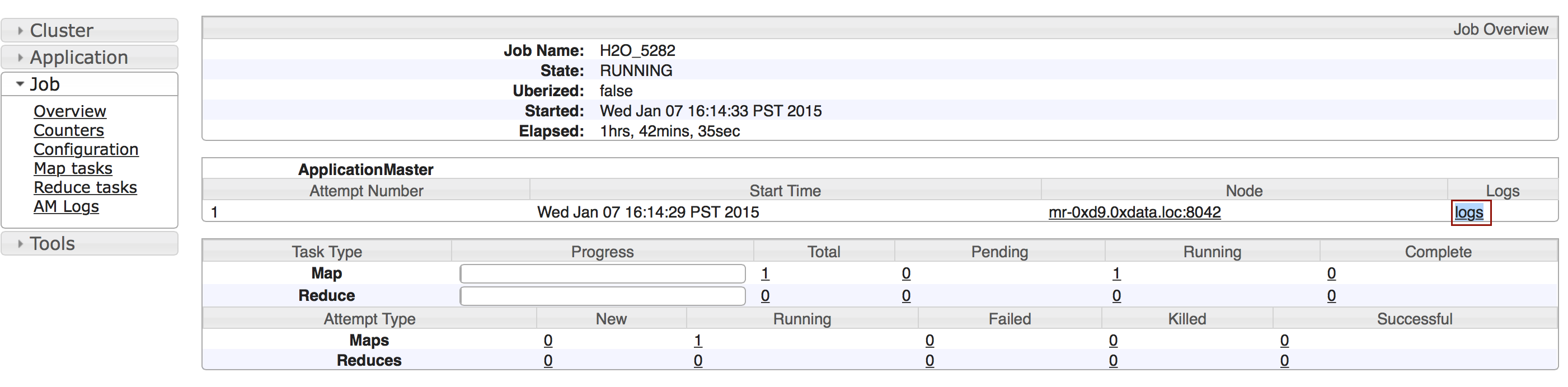
Send the contents of the displayed files to support@h2o.ai.

- (H2O1) Go to the H2O web UI and select Admin > Inspect Log or go to http://localhost:54321/LogView.html. To download the logs, click the Download Logs button.
When you view the log, the output displays the location of log directory after Log dir: (as shown in the last line in the following example):
08-Jan 12:27:39.099 172.16.2.188:54321 28195 main INFO WATER: ----- H2O started -----
08-Jan 12:27:39.100 172.16.2.188:54321 28195 main INFO WATER: Build git branch: rel-mirzakhani
08-Jan 12:27:39.100 172.16.2.188:54321 28195 main INFO WATER: Build git hash: ae31ed04e47d826b73e7180e07ba00db13e879f3
08-Jan 12:27:39.100 172.16.2.188:54321 28195 main INFO WATER: Build git describe: jenkins-rel-mirzakhani-2
08-Jan 12:27:39.100 172.16.2.188:54321 28195 main INFO WATER: Build project version: 2.8.3.2
08-Jan 12:27:39.101 172.16.2.188:54321 28195 main INFO WATER: Built by: 'jenkins'
08-Jan 12:27:39.101 172.16.2.188:54321 28195 main INFO WATER: Built on: 'Thu Dec 18 18:54:25 PST 2014'
08-Jan 12:27:39.101 172.16.2.188:54321 28195 main INFO WATER: Java availableProcessors: 32
08-Jan 12:27:39.102 172.16.2.188:54321 28195 main INFO WATER: Java heap totalMemory: 0.96 gb
08-Jan 12:27:39.102 172.16.2.188:54321 28195 main INFO WATER: Java heap maxMemory: 0.96 gb
08-Jan 12:27:39.102 172.16.2.188:54321 28195 main INFO WATER: Java version: Java 1.7.0_72 (from Oracle Corporation)
08-Jan 12:27:39.103 172.16.2.188:54321 28195 main INFO WATER: OS version: Linux 3.13.0-43-generic (amd64)
08-Jan 12:27:39.106 172.16.2.188:54321 28195 main INFO WATER: Machine physical memory: 251.89 gb
08-Jan 12:27:39.235 172.16.2.188:54321 28195 main INFO WATER: ICE root: '/home2/hdp/yarn/usercache/H2O-User/appcache/application_1420450259209_0017'
08-Jan 12:27:39.238 172.16.2.188:54321 28195 main INFO WATER: Possible IP Address: br2 (br2), 172.16.2.188
08-Jan 12:27:39.238 172.16.2.188:54321 28195 main INFO WATER: Possible IP Address: lo (lo), 127.0.0.1
08-Jan 12:27:39.330 172.16.2.188:54321 28195 main INFO WATER: Internal communication uses port: 54322
+ Listening for HTTP and REST traffic on http://172.16.2.188:54321/
08-Jan 12:27:39.372 172.16.2.188:54321 28195 main INFO WATER: H2O cloud name: 'H2O_45911'
08-Jan 12:27:39.372 172.16.2.188:54321 28195 main INFO WATER: (v2.8.3.2) 'H2O_45911' on /172.16.2.188:54321, discovery address /237.88.97.222:60760
08-Jan 12:27:39.372 172.16.2.188:54321 28195 main INFO WATER: If you have trouble connecting, try SSH tunneling from your local machine (e.g., via port 55555):
+ 1. Open a terminal and run 'ssh -L 55555:localhost:54321 yarn@172.16.2.188'
+ 2. Point your browser to http://localhost:55555
08-Jan 12:27:39.377 172.16.2.188:54321 28195 main DEBG WATER: Announcing new Cloud Membership: [/172.16.2.188:54321]
08-Jan 12:27:39.379 172.16.2.188:54321 28195 main INFO WATER: Cloud of size 1 formed [/172.16.2.188:54321 (00:00:00.000)]
08-Jan 12:27:39.379 172.16.2.188:54321 28195 main INFO WATER: Log dir: '/home2/hdp/yarn/usercache/H2O-User/appcache/application_1420450259209_0017/h2ologs'
- (H2O1) In Terminal, enter cd /tmp/h2o-<UserName>/h2ologs (where <UserName> is your computer user name), then enter ls -l to view a list of the log files. The httpd log contains the request/response status of all REST API transactions.
The rest of the logs use the format h2o_\<IPaddress>\_<Port>-<LogLevel>-<LogLevelName>.log, where <IPaddress> is the bind address of the H2O instance, <Port> is the port number, <LogLevel> is the numerical log level (1-6, with 6 as the highest severity level), and <LogLevelName> is the name of the log level (trace, debug, info, warn, error, or fatal).
- (H2O1) Download the logs using R. In R, enter the command h2o.downloadAllLogs(client = localH2O,filename = "logs.zip") (where client is the H2O cluster and filename is the specified filename for the logs).
Accessing YARN¶
Methods for accessing YARN vary depending on the default management software and version, as well as job status.
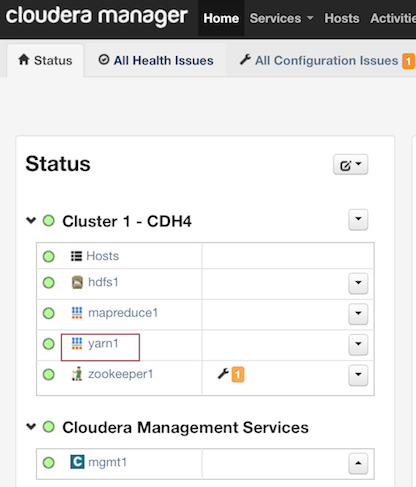
Cloudera 4¶
- In Cloudera Manager, click the yarn link in the cluster section.
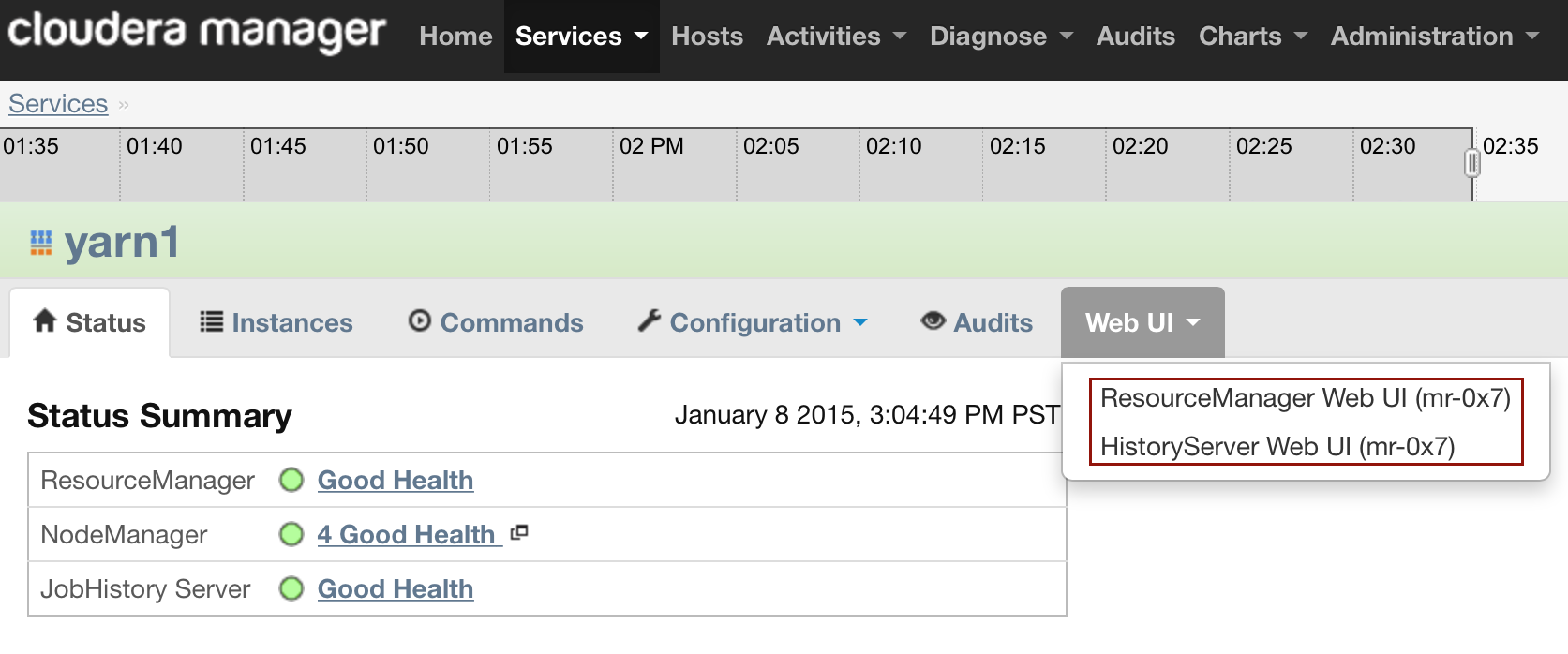
- Click the Web UI drop-down menu. If the job is running, select ResourceManager Web UI. If the job is not running, select HistoryServer Web UI.
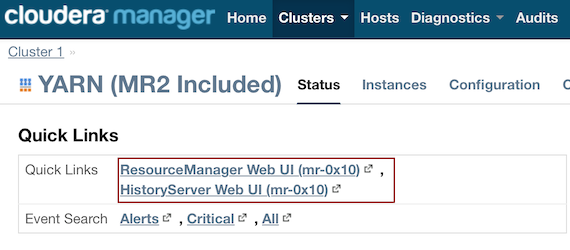
Cloudera 5¶
- In Cloudera Manager, click the YARN link in the cluster section.
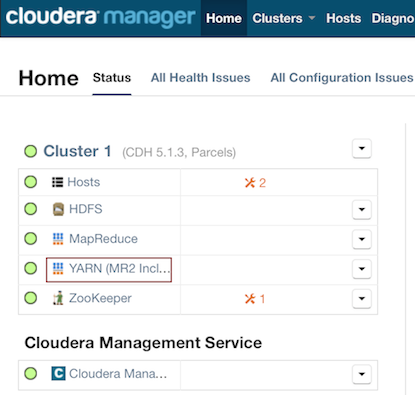
- In the Quick Links section, select ResourceManager Web UI if the job is running or select HistoryServer Web UI if the job is not running.
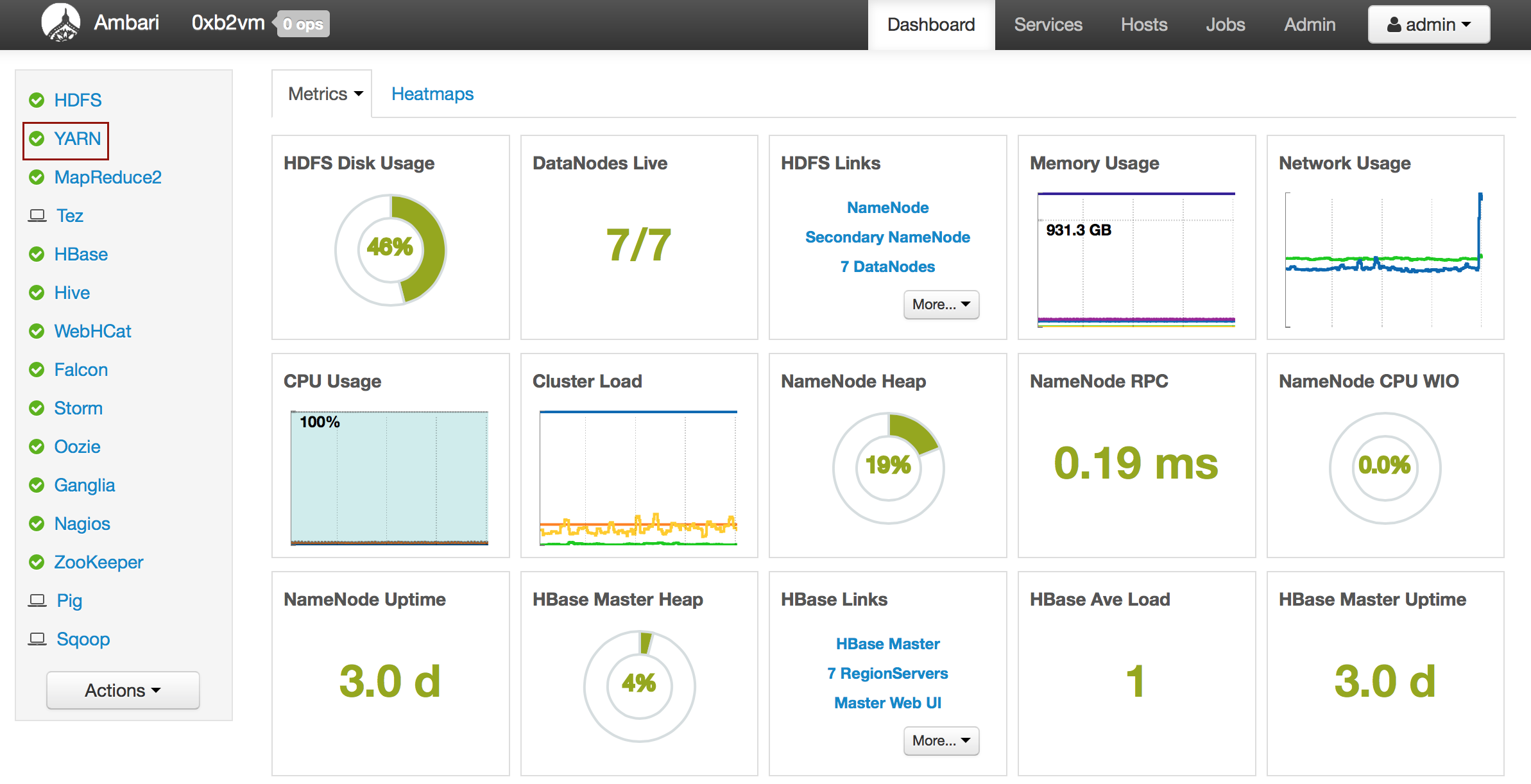
Ambari¶
- From the Ambari Dashboard, select YARN.
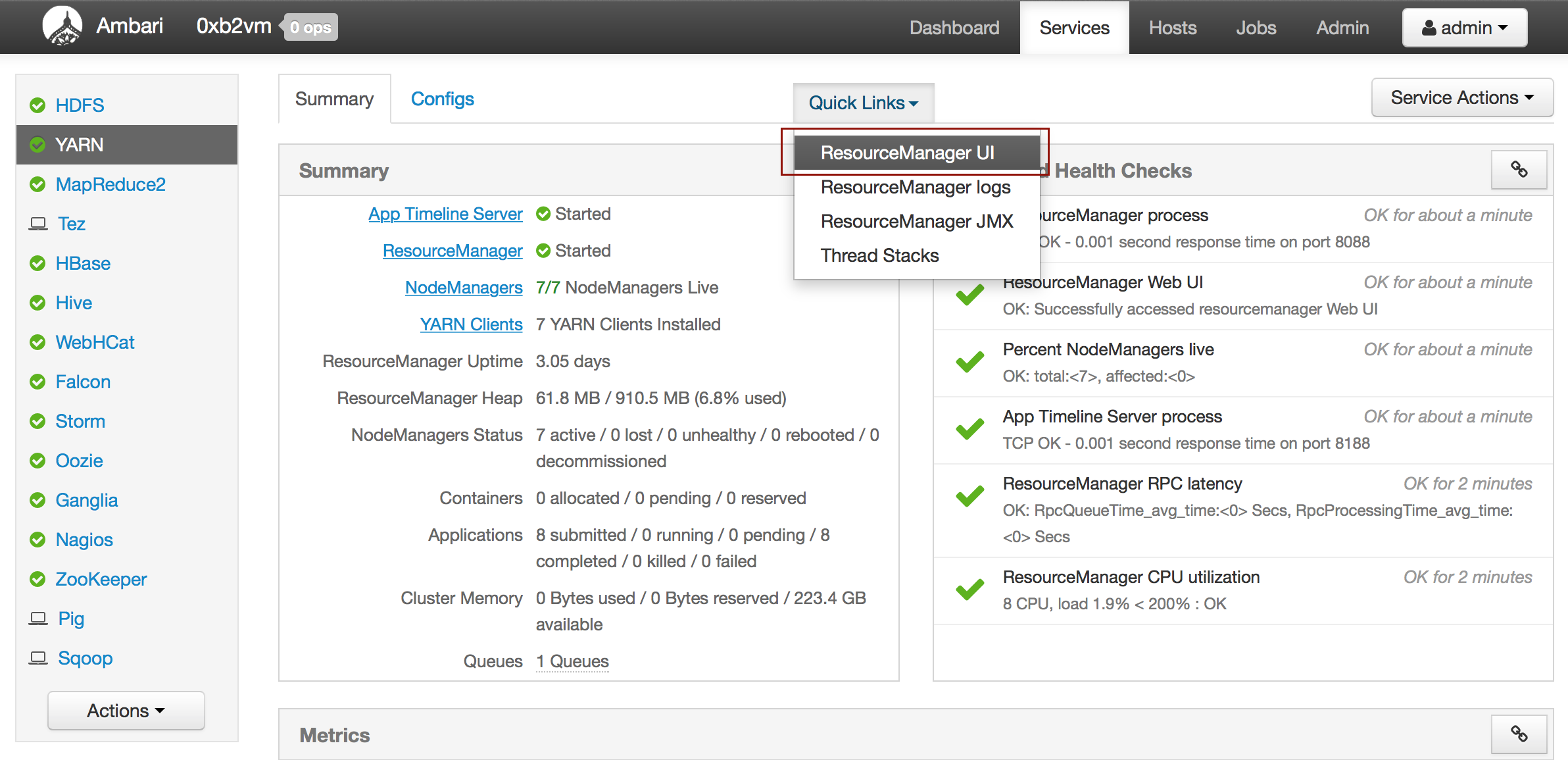
- From the Quick Links drop-down menu, select ResourceManager UI.
Common Hadoop Questions¶
What versions of Hadoop are supported?
Currently, the major versions that H2O supports are HDP 1.3 and HDP 2.1. H2O also supports MapR 2.1 and 3.1, as well as CDH 4 and 5.
What’s the syntax for the file path of a data set sitting in hdfs?
To locate an HDFS file, go to Data > Import and enter hdfs:// in the path field. H2O automatically detects any HDFS paths. This is a good way to verify the path to your data set before importing through R or any other non-web API.
When interacting with an H2O cluster launched on multiple Hadoop nodes, is it necessary for R to be installed on all the data nodes?
No - as long as the R instance can communicate with one of the nodes in the network, R can be installed on any of the nodes, or even on a local machine that will securely tunnel into the cluster.
Is it possible to launch the H2O cluster on Hadoop nodes using R’s h2o.init() command?
No - follow the instructions in Running H2O on Hadoop and add the IP address to the h2o.init() function to connect to the cluster.
What does "ERROR: Output directory hdfs://sandbox.hortonworks.com:8020/user/root/hdfsOutputDir already exists?" mean?
Each mapper task gets its own output directory in HDFS. To prevent overwriting multiple users’ files, each mapper task must have a unique output directory name. Change the -output hdfsOutputDir argument to -output hdfsOutputDir1 and the task should launch.
What should I do if H2O starts to launch but times out in 120 seconds?
- YARN or MapReduce’s configuration is not configured correctly. Enable launching for mapper tasks of specified memory sizes. If YARN only allows mapper tasks with a maximum memory size of 1g and the request requires 2g, then the request will timeout at the default of 120 seconds. Read Configuration Setup to make sure your setup will run.
- The nodes are not communicating with each other. If you request a cluster of two nodes and the output shows a stall in reporting the other nodes and forming a cluster (as shown in the following example), check that the security settings for the network connection between the two nodes are not preventing the nodes from communicating with each other. You should also check to make sure that the flatfile that is generated and being passed has the correct home address; if there are multiple local IP addresses, this could be an issue.
$ hadoop jar h2odriver_horton.jar water.hadoop.h2odriver -libjars ../h2o.jar
-driverif 10.115.201.59 -timeout 1800 -mapperXmx 1g -nodes 2 -output hdfsOutputDirName
13/10/17 08:51:14 INFO util.NativeCodeLoader: Loaded the native-hadoop library
13/10/17 08:51:14 INFO security.JniBasedUnixGroupsMapping: Using JniBasedUnixGroupsMapping for
Group resolution
Using mapper->driver callback IP address and port: 10.115.201.59:34389
(You can override these with -driverif and -driverport.)
Driver program compiled with MapReduce V1 (Classic)
Memory Settings:
mapred.child.java.opts: -Xms1g -Xmx1g
mapred.map.child.java.opts: -Xms1g -Xmx1g
Extra memory percent: 10
mapreduce.map.memory.mb: 1126
Job name 'H2O_61026' submitted
JobTracker job ID is 'job_201310092016_36664'
Waiting for H2O cluster to come up...
H2O node 10.115.57.45:54321 requested flatfile
H2O node 10.115.5.25:54321 requested flatfile
Sending flatfiles to nodes...
[Sending flatfile to node 10.115.57.45:54321]
[Sending flatfile to node 10.115.5.25:54321]
H2O node 10.115.57.45:54321 reports H2O cluster size 1
H2O node 10.115.5.25:54321 reports H2O cluster size 1
What should I do if the H2O job launches but terminates after 600 seconds?
The likely cause is a driver mismatch - check to make sure the Hadoop distribution matches the driver jar file used to launch H2O. If your distribution is not currently available in the package, email us for a new driver file.