GLM Tutorial¶
The purpose of this tutorial is to walk the new user through a GLM analysis beginning to end. The objective is to learn how to specify, run, and interpret a GLM model using H2O.
Those who have never used H2O before should see see Getting Started from a Downloaded Zip File for additional instructions on how to run H2O.
When to Use GLM¶
The variable of interest relates to predictions or inferences about a rate, an event, or a continuous measurement. Questions are about how a set of environmental conditions influence the dependent variable.
Here are some examples:
“What attributes determine which customers will purchase, and which will not?”
“Given a set of specific manufacturing conditions, how many units produced will fail?”
“How many customers will contact help support in a given time frame?”
“Given a set of conditions, which units will fail?”
Getting Started¶
This tutorial uses a publicly available data set that can be found at:
http://archive.ics.uci.edu/ml/machine-learning-databases/abalone/
The original data are the Abalone data set made available by UCI Machine Learning Repository. They are composed of 4177 observations of 9 attributes. All attributes are real valued continuous, except for Sex and Rings, found in columns 0 and 8 respectively. Sex is categorical with 3 levels (male, female, and infant), and Rings is integer valued.
Before modeling, parse data into H2O as follows:
- Under the drop down menu Data select Upload, and use the helper to upload data.
- User will be redirected to a page with the header “Request Parse”. Select whether the first row of the data set is a header. All other settings can be left in default. Press Submit.
- Parsing data into H2O generates a .hex key (“data name.hex”)
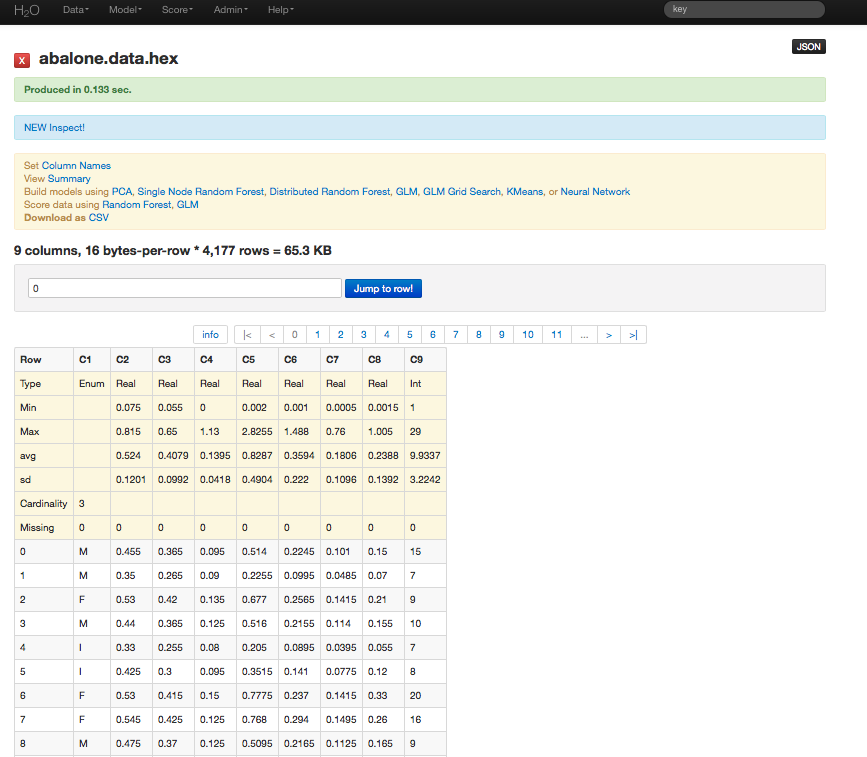
Building a Model¶
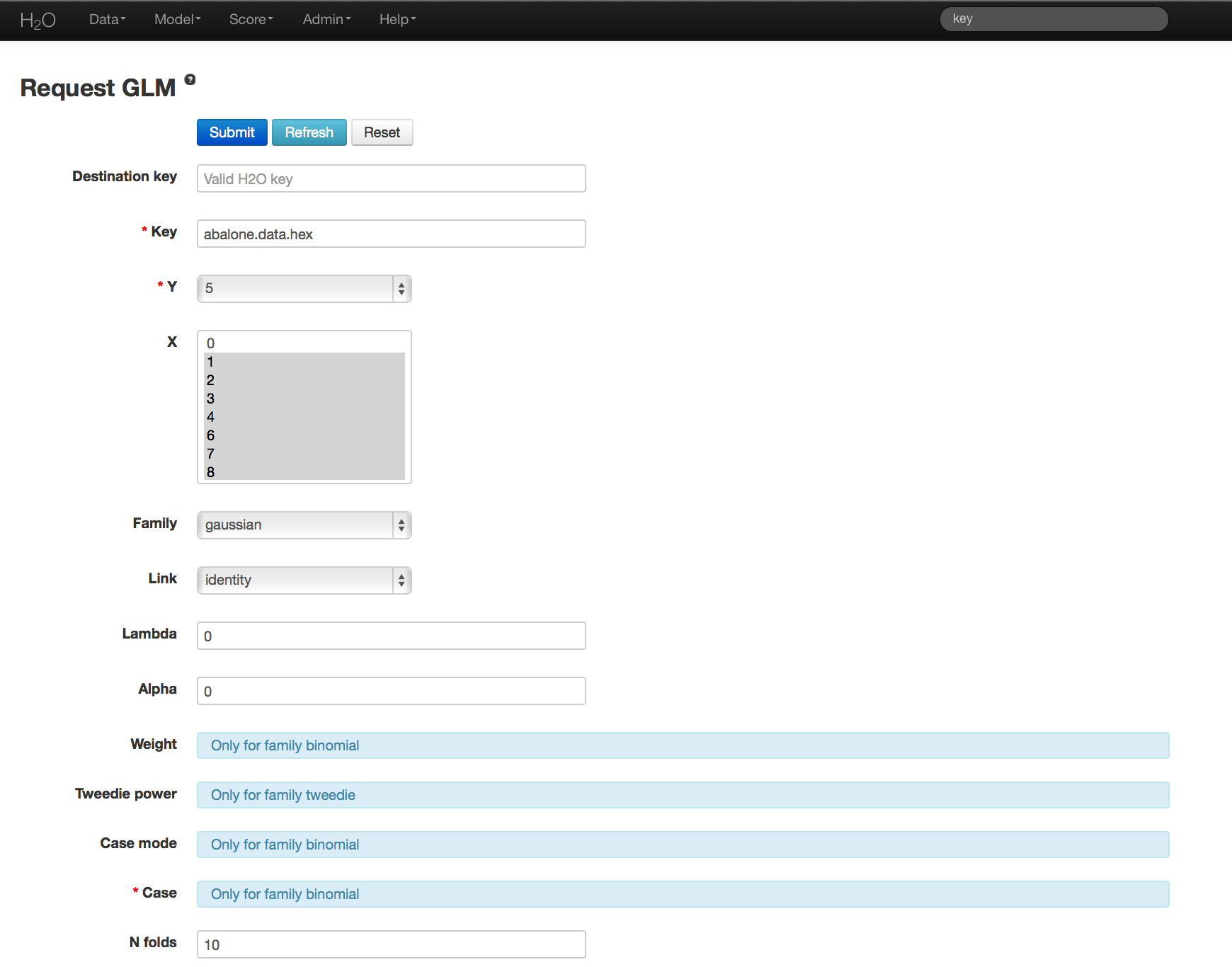
- Once data are parsed, a horizontal menu will appear at the top of the screen reading “Build model using ... ”. Select GLM here, or go to the drop down menu Model and select GLM.
- In the Key field enter the .hex key for the data set.
- In the Y field select the column associated with the Whole Weight variable (column 5).
- In the X field select the columns associated with Sex, Length, Diameter, Height, and Rings (all other columns).
- Specify the distribution family to be Gaussian. This automatically sets the link field to identity.
- Set lambda and alpha to 0. These parameters determine regularization of GLM models. To find detailed information on the specification of tuning parameters see Generalized Linear Model (GLM).
- Leave n-folds at 10. This will produce 10 cross-validation models.
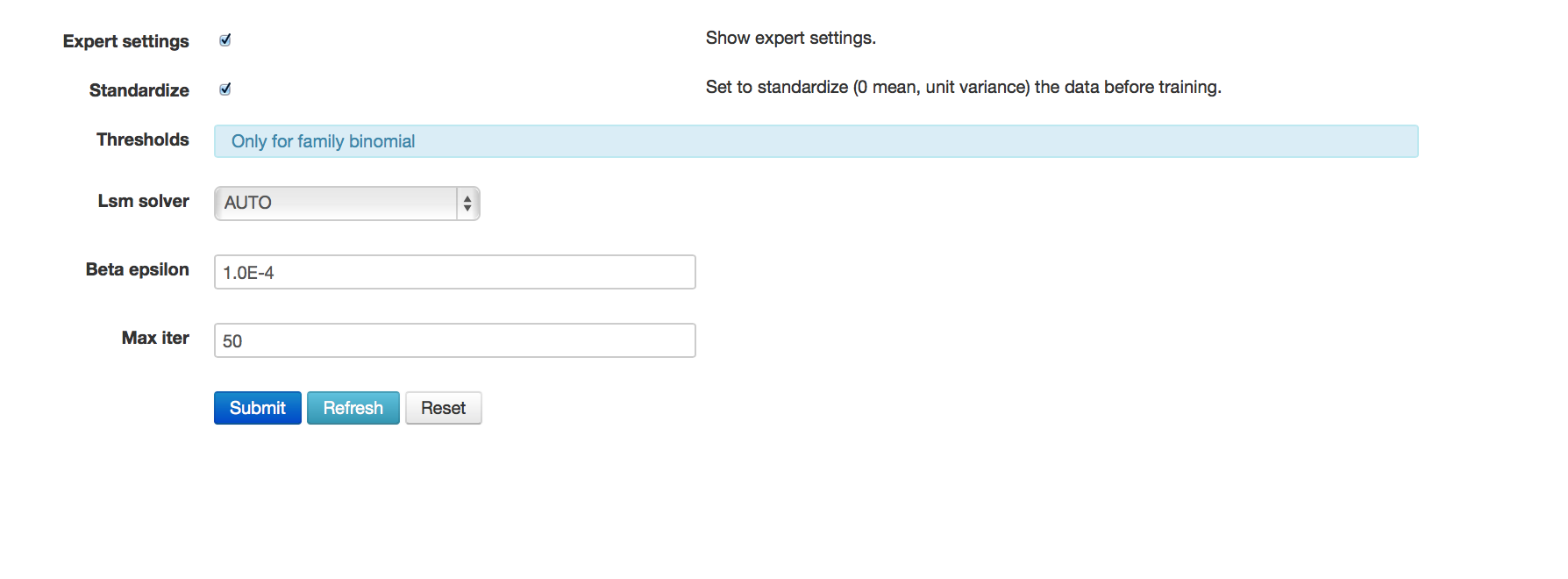
- Under the options box marked expert settings, notice that standardization is ON by default. This option returns two sets of coefficients, the non-standardized coefficients, and standardized coefficients.
Additional specification detail
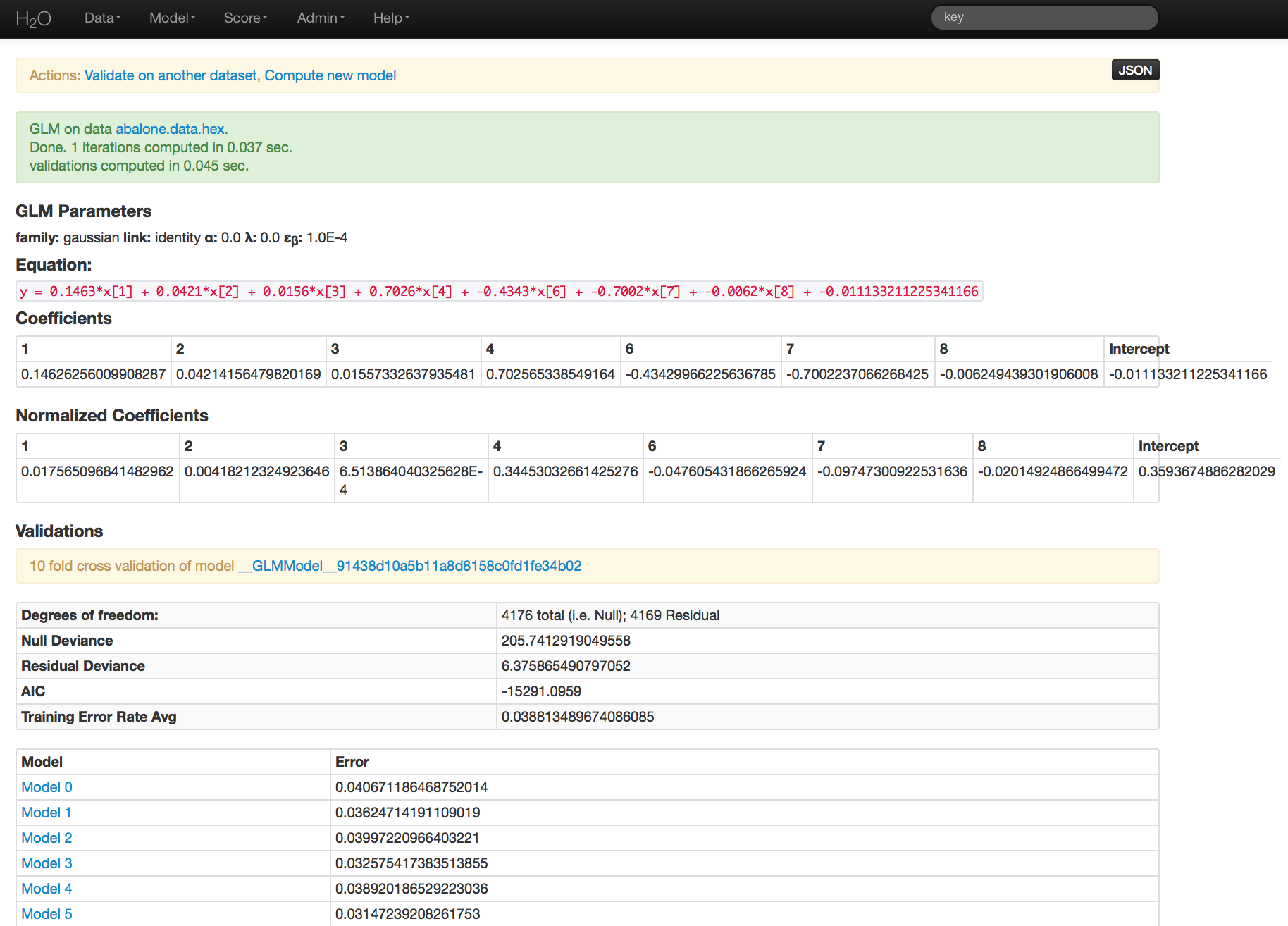
GLM Results¶
GLM output includes coefficients (as well as normalized coefficients when standardization is requested). Also reported are AIC and error rate. An equation of the specified model is printed across the top of the GLM results page in red.
Users should note that if they wish to replicate results between H2O and R, it is recommended that standardization and cross validation either be turned off in H2O.
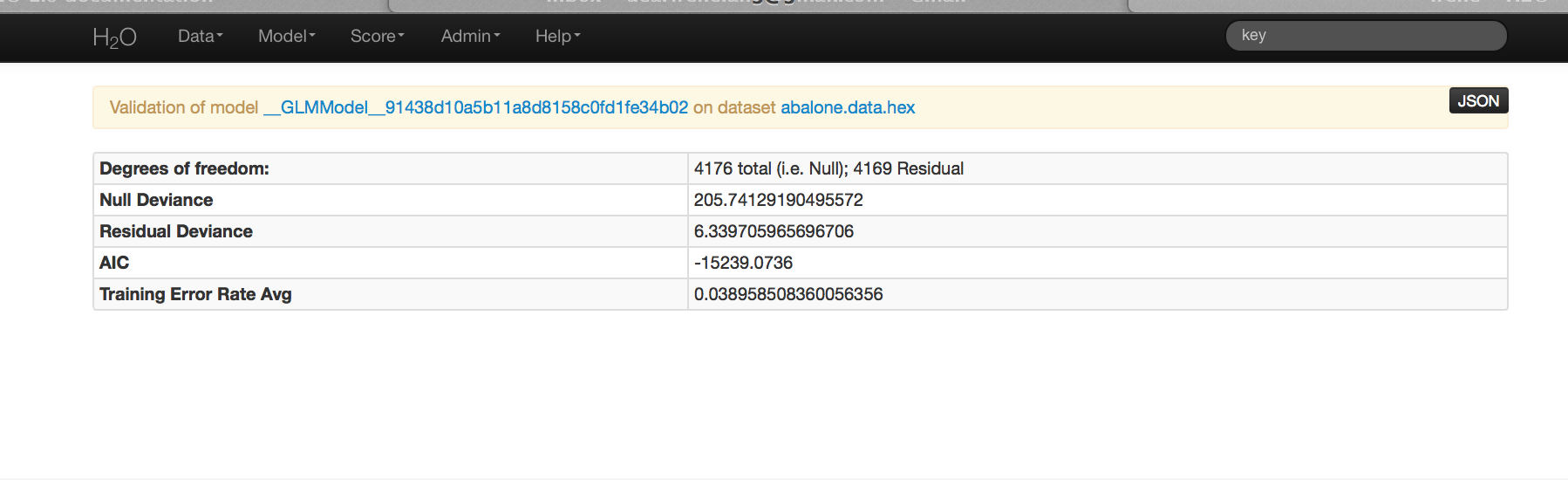
Validating on Testing Set¶
- Models can be applied to holdout testing sets or prediction data, provided that the data are in the same format as the data originally used to generate the GLM model.
- At the top of the GLM results page is a horizontal menu titled Actions. Select Validate On Another Dataset. This same action can be completed by going to the Score drop down menu and selecting GLM.
- In model key enter the .hex key found in the center of the GLM results page under the header Validations (this can also be found under the Admin drop down menu by selecting Jobs).
- In the Key field enter the .hex key associated with the testing data set. Press submit.
Validation results report the same model statistics as were generated when the model was originally specified.
THE END.